
UNC graduate student Ben Brunk sits in front of a computer station, but not just any ordinary station. He’s wearing a band around his head to track his movements. A camera mounted on a tall wooden structure behind him records his actions, and a software program logs his keystrokes. An eye-tracking device, seated on a tower of Legos, maps his eye movement and pupil dilation. In today’s world the setup is clunky, but 21 years ago this was cutting edge.

Images from the Endeavors’ article, published in winter of 2000, shows the Interaction Design Lab’s eye tracking station.
Brunk was demonstrating an experiment in the School of Information and Library Science’s (SILS) Interaction Design Lab for an article in Endeavors’ magazine, published in the winter of 2000.
The team wanted to better understand how people navigate the internet.
“Today this stuff is trivial, but that set up was about $30,000. And just to get the thing to work was painful,” Gary Marchionini, former director of the lab and now dean of SILS, says with a laugh. “You’d lose data, and it would go out of calibration, and you’d have to start over.”
While the technology has drastically improved, the goal of the researchers has remained — understanding how people form and navigate queries in order to improve information retrieval systems. They use a combination of psychology, computing, and information science to answer those questions.
“We weren’t trying to create the systems, per se. We weren’t building startup companies,” Marchionini explains. “We were trying to understand people’s behavior, which would then inform good design.”
Exploring a visual wave
Want to know how to make the perfect gumbo? If a Roth or SEP IRA is better for your retirement plan? If penguins have knees? Today, the possibilities are endless when it comes to finding information via the internet, but not long ago it was much more complicated.
When Marchionini began at UNC in 1998, the World Wide Web was still in its infancy.
Websites were cumbersome and their back-end indexing was basic. Lycos and Yahoo existed, but Google, founded that year, wouldn’t become mainstream for some time. A big hurdle for users was just finding what was out there. In other words, the internet was not the cornucopia of information it is today, and experts were working to make information more findable.
While many were focused on how to improve retrieval of text, Marchionini had an eye on what was to come: video. “Videos were big, giant files with all these technical problems,” he says. “We were interested in how people think about video, how they’re looking for video.”
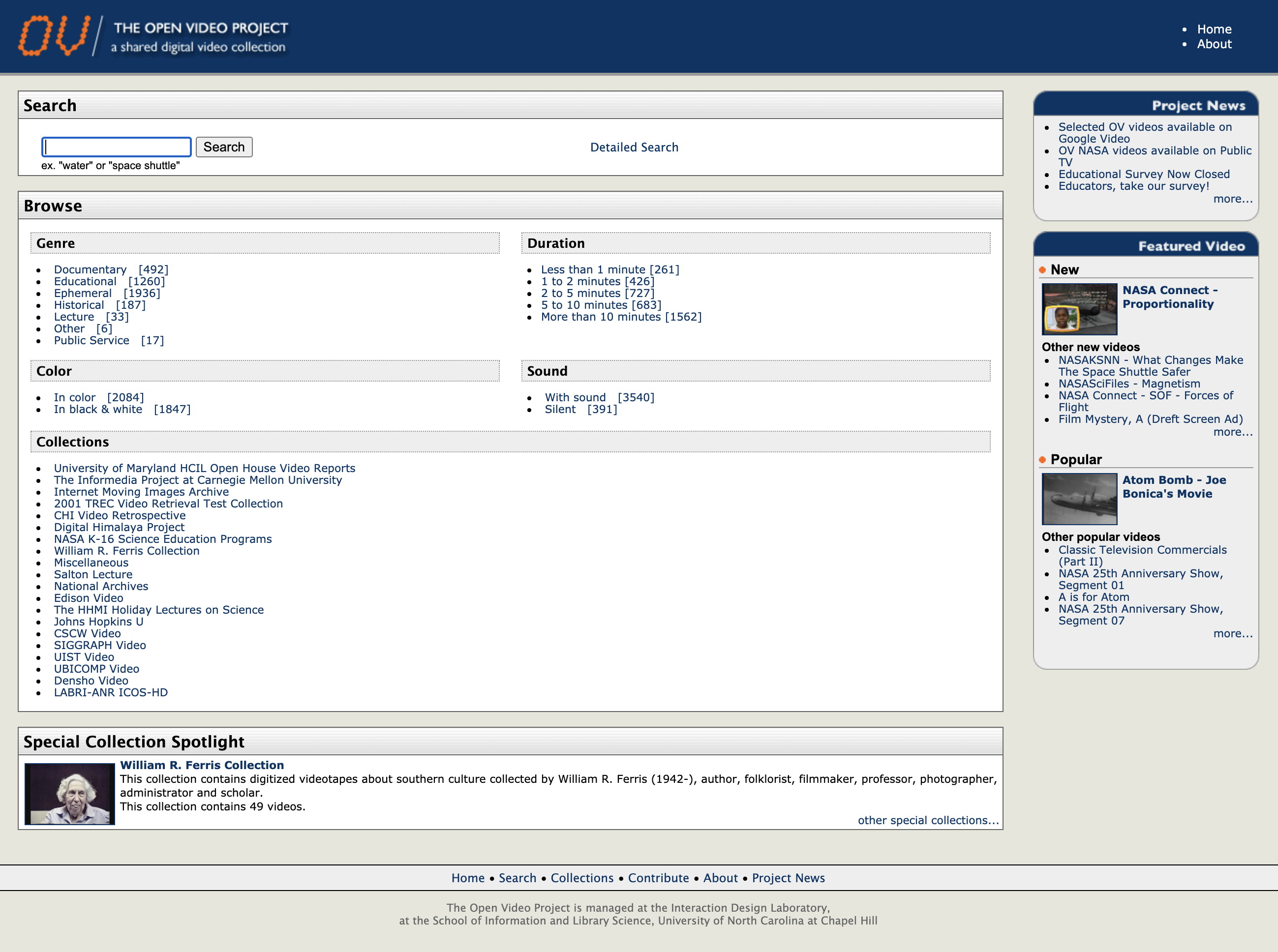
The Open Video Project, created in 2000, is a database of searchable videos. Users could submit their own videos and download videos from the site.
Did people rely on text searches related to the content or were they searching based on visual clues like color, shapes, or the prevalence of faces? To find out, the team talked to art librarians and television producers to learn how they archived content and conducted eye-tracking experiments to understand what people focused on when searching for video online. Then, they created a system based on their empirical findings.
Before YouTube, there was The Open Video Project — a shared digital video collection created in 2000.
“Gary was on the leading edge of a lot of this video retrieval stuff,” says Rob Capra, an associate professor at SILS. “Stuff that YouTube and other companies do now, Gary’s open video project was looking at a long time ago.”
The project was a compilation of a few thousand open-sourced videos. Search results could be filtered by things like genre, duration, topic, if the video was black and white or in color, and if it had audio. Users could not only download content, they could also submit their own. Sound familiar?
The work led to a collaboration with Google to build a foundational archive for their video retrieval system, and a partnership with YouTube to create a channel for UNC, which launched in 2008.
While research showed that people, by in large, used text queries when searching for video, Marchionini wanted to push those boundaries by incorporating visuals into the search process. Enter the keyframe.
Unlocking the power of key frames
In the Endeavors article back in 2000, Marchionini stated “a click is a terrible thing to waste.”
“When people were searching the internet, they’d click on something and kind of go down this rabbit hole and get lost. It was called ‘lost in hyperspace.’ Plus, systems were slow so there was a lot of waiting for pages to load,” he says now. “What people tended to do as a strategy was to just start all over — they’d jump all the way back to the top of a menu hierarchy and work their way down again.”
At the time, the notion of wasting clicks was also applicable to navigating large and slow video files. Marchionini thought incorporating some sort of video preview might cut down on search time — if users could see a single or set of frames from a video, they can easily decide if they want to go ahead and watch the video or continue with their search.
“The New Yorker always had great covers, and in 1989 they published 64 years of their magazine covers in a book,” Marchionini says. “I was wondering, If I take the pages and flip through it real quick, what would I recognize? How much would I be able to get from that?”
Marchionini’s research question became, how fast is too fast? He wanted to determine a user’s speed limit of image recognition, so he created a pseudo fast-forward. In their studies, his team pulled images from videos at a set interval of 256, 128, 64, and 32 frames. Participants would watch the compilation of pulled frames and then answer questions about the content.

Gary Marchionini, Dean of UNC School of Information and Library Science (photo by Jon Gardiner/UNC-Chapel Hill).
“It was pretty amazing,” he says. “Taking a 10-minute video and extracting every 256th frame compacts it down to just a few seconds, and people were still able to infer things. So, 256 was kind of on the edge, 128 was a bit better, and 64 seemed pretty good.”
Based on the findings, the team chose the last of these as the fast-forward rate for The Open Video Project. But Marchionini wasn’t done exploring how to ease video retrieval. When a video is displayed online, users see a keyframe — an image that summarizes the video. Many systems just picked a frame from the beginning, middle, or end of the video, but Marchionini thought he could do better.
“We developed strategies based on the assumption that a scene change is a pretty important piece of a video,” he says. “So, could we automatically identify a scene change?”
They could. Most of the time, a scene change correlates to a change in the video’s histogram — a measure of light distribution in an image. Say a video shows someone shopping in a grocery store and then the next scene they’re out in the parking lot. The histogram automatically picks up on changes in elements like light, saturation, and color.
“You just look for when the histogram has changed dramatically and you pick a frame after that. So those became keyframes, just like key words,” Marchionini says.
While most systems employed the use of just one keyframe, Marchionini thought incorporating more would be better.
“We said, Let’s pick the best 10 keyframes or the best 30. Show the overview of what the video is about so people don’t have to watch the whole video to make sense of it. If the preview fits what they’re looking for then they can go on to watch the whole thing.”
Today, this technique is widespread — YouTube uses keyframe scrolling on video timelines, Google video searches provide a keyframe in the results list, and video editing software like Adobe Premiere allows users to scroll through videos in their library.
Marchionini is now in his 11th year as the dean of SILS. His focus has shifted from hands-on research to continuing growth at SILS, and supporting the exceptional group of faculty and students in the school.
“The lab today is still studying information seeking behavior, but looking at different kinds of problems,” he says. “In most ways, I’ve turned this over to younger faculty. We’ve been able to attract and hire good people who have really driven and continued this work.”
One of those people has been Rob Capra, who, along with Jaime Arguello, runs the UNC Interactive Information Systems Lab.
Navigating today’s internet
While search engine systems have improved over the past few decades, their basic format has remained largely unchanged — queries are answered via a ranked list of results. Capra and his colleagues at the Interactive Information Systems Lab think there’s room for improvement.
“What we’ve been focusing on is how search engines and users can work together in an interface where users can provide more information about the context of their task and the search system can provide more help toward getting people to their learning or broader objectives,” Capra says.
Say you’re given a medical diagnosis and want to learn all the different aspects of that condition. That’s not about finding one particular piece of information, Capra explains, it’s about building a comprehensive collection of information.
At the beginning of the process, you might do a broad overview search just to learn about the medical condition. Later on, you might narrow that down to comparing treatment options and other patients’ experiences.
“Ranked results work great, but sometimes you need more than that,” Capra says. “We wanted to develop systems that will help people find more appropriate information for what they’re trying to do.”
The lab built a set of filters that sits alongside search results. Study participants were given a variety of search tasks with different levels of complexity. As they searched, they could filter queries based on the different types of information they’re seeking, like factual information, broad background concepts, and opinions. Participants weren’t forced to use the filters, instead the tools were presented as options they could use on their own terms.

Bogeum Choi test runs an experiment on user’s search patterns as Austin Ward looks on in the SILS’ Interactive Information Science Laboratory (photo by Elise Mahon).
Study results showed that when people were given tasks like basic information retrieval they focused on sources that provide background information. When given complex tasks like those involving creating or designing things, users relied more on results based on other people’s experiences and opinions, like blogs or forums.
“So, using the tool we were able to see what type of information filtering people used based on the task they were given,” Capra says. “It was really cool.”
Another concept the lab is focused on falls along the line of collaborative searching, exploring how people can use others’ “search trails” in their own investigations.
Imagine you’re making homemade pizza and having a hard time getting your dough to rise. You hop on the computer and, after spending some time digging around on multiple sites, you find your solution. The next day someone else hits up Google with the same problem. Instead of spending a bunch of time doing their own research, would it be beneficial for that new person to see the search path you followed? Capra notes that to protect users’ privacy, such a system would be based on users voluntarily choosing to share search sessions.
The lab created a widget that could help users navigate others’ search trails. Study participants were again given search tasks. They were told to use the widget if they’d like, or they could go about the search entirely on their own. Results showed that most participants started out on their own, but would turn to the widget when they got stuck or wanted to verify their findings.
“Ways of filtering information types, having tools built in and integrated with the search engine as a tool you collaborate with to make sense of the information and organize it — those are things I’m super excited about and hope we’ll see implemented more in the future,” Capra says.
Years ago, Marchionini’s video research was at the forefront of the field. Capra is confident that current work coming out of the Information Interactive Systems Lab will be the next chapter.